
Table of Contents
Neural Network
Neural Network NN
AKA “neural net”. A network of neurons. In biology, the neocortex of the brain is an example of a neural network.
Artificial Neural Network ANN
Mathematicians have attempted to mimic the human brain by stringing together networks of functions. This is the state of the art in the field of AI. There are many variations on the idea.
Convolutional Neural Network CNN
Perceptron
binary classifier
spreadsheet implementation of a perceptron https://docs.google.com/spreadsheets/d/1iPkTdAvykzNR0y-lOkjnjGaGr4TXuHlfRzQby7VOXhU/edit#gid=0
python tensorflow implementaton of a perceptron https://curriculum.voyc.com/doku.php?id=tensorflow_python_examples#perceptron_neuron_and_gate
Multilayer Perceptron
Fully Connected Neural Network == Neural Network
Is there a “partially connected neural network”?
Neural Network == Multilayer Perceptron
weighted sum of inputs and weights \begin{align*}z^{(i)} = w_{1}x_{1}^{(i)} + w_{2}x_{2}^{(i)} + .. .+ w_{k}x_{k}^{(i)} + b,\end{align*}
2 layer nn
Build a neural network from scratch using python and numpy https://m.youtube.com/watch?v=w8yWXqWQYmU
Recurrent Neural Network RNN
A single network can repeat recursively for each data point in a series. Consider a time series of stock prices: one price per day for 7 days, or 30 days, or 100 days. You could build a neural network with an input layer of 7 inputs, or 30 inputs, or 100 inputs. Or you could build a single recurrent neural network with one input, and let it recur once for each stock price in the time series. https://www.youtube.com/watch?v=AsNTP8Kwu80
Convolutional Neural Network CNN
How it Works
https://www.baeldung.com/cs/convolutional-vs-regular-nn
IK means multiply I times K
I * K means convolve K over I
I is the input matrix
K is the kernel or filter
result of the convolution layer is the convolved feature map
result of the pooling layer is the pooled feature map
Unlike an artificial neuron in a fully-connected layer, a neuron in a convolutional layer is not connected to the entire input but just some section of the input data. These input neurons provide abstractions of small sections of the input data that, when combined over the entire input, we refer to as a feature map.
feature extraction
Basically, the artificial neurons in CNN are arranged into 2D or 3D grids which we call filters. Usually, each filter extracts the different types of features from the input data. For example, from the image, one filter can extract edges, lines, circles, or more complex shapes.
convolutional function
The process of extracting features uses a convolution function, and from that comes the name convolutional neural network. The figure below shows the matrix I to apply the convolution using filter K. This means that filter K passes through matrix I, and an element-by-element multiplication is applied between the corresponding element of the matrix I and filter K. Then, we sum the results of this multiplication into a number:
Variations
three primary object detectors you’ll encounter:
- R-CNN and their variants, including the original R-CNN, Fast R- CNN, and Faster R-CNN
- Single Shot Detector (SSDs)
- YOLO
R-CNNs are one of the first deep learning-based object detectors and are an example of a two-stage detector.
R-CNN Rich feature hierarchies for accurate object detection and semantic segmentation, (2013) Girshick et al. https://arxiv.org/abs/1311.2524 proposed an object detector that required an algorithm such as Selective Search (or equivalent) to propose candidate bounding boxes that could contain objects.
These regions were then passed into a CNN for classification, ultimately leading to one of the first deep learning-based object detectors.
The problem with the standard R-CNN method was that it was painfully slow and not a complete end-to-end object detector.
Fast R-CNN, (2013) Girshick et al. https://arxiv.org/abs/1504.08083
The Fast R-CNN algorithm made considerable improvements to the original R-CNN, namely increasing accuracy and reducing the time it took to perform a forward pass; however, the model still relied on an external region proposal algorithm.
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks, (2015) Girshick et al. https://arxiv.org/abs/1506.01497
R-CNNs became a true end-to-end deep learning object detector by removing the Selective Search requirement and instead relying on a Region Proposal Network (RPN) that is (1) fully convolutional and (2) can predict the object bounding boxes and “objectness” scores (i.e., a score quantifying how likely it is a region of an image may contain an image). The outputs of the RPNs are then passed into the R-CNN component for final classification and labeling.
While R-CNNs tend to be very accurate, the biggest problem with the R-CNN family of networks is their speed — they were incredibly slow, obtaining only 5 FPS on a GPU.
You Only Look Once YOLO
YOLOv1 2015 Joseph Ched Redmon et al
YOLOv2 2016 Redmon and Farhadi, aka YOLO9000
YOLOv3 2018 Redmon last version for Redmon, he bails out due to concerns about military applications
YOLOv4 2020 Alexey Bochkovskiy et al: YOLOv4: Optimal Speed and Accuracy of Object Detection
YOLOv5 Ultralytics, switch from DarkNet to PyTorch
YOLOv6 Alexey Bochkovskiy et al
YOLOv7 Alexey Bochkovskiy et al
YOLOv8 Ultralytics
YOLOv9 ?
https://deci.ai/blog/history-yolo-object-detection-models-from-yolov1-yolov8/
Invented by Joseph Chet Redmon https://pjreddie.com/
To help increase the speed of deep learning-based object detectors, both Single Shot Detectors (SSDs) and YOLO use a one-stage detector strategy.
These algorithms treat object detection as a regression problem, taking a given input image and simultaneously learning bounding box coordinates and corresponding class label probabilities.
In general, single-stage detectors tend to be less accurate than two-stage detectors but are significantly faster.
YOLO is a great example of a single stage detector.
“You Only Look Once: Unified, Real-Time Object Detection” 2015, Redmon et al. details an object detector capable of super real-time object detection, obtaining 45 FPS on a GPU.
Note: A smaller variant of their model called “Fast YOLO” claims to achieve 155 FPS on a GPU.
YOLO has gone through a number of different iterations, including YOLO9000: Better, Faster, Stronger (i.e., YOLOv2), capable of detecting over 9,000 object detectors.
Redmon and Farhadi are able to achieve such a large number of object detections by performing joint training for both object detection and classification. Using joint training the authors trained YOLO9000 simultaneously on both the ImageNet classification dataset and COCO detection dataset. The result is a YOLO model, called YOLO9000, that can predict detections for object classes that don’t have labeled detection data.
While interesting and novel, YOLOv2’s performance was a bit underwhelming given the title and abstract of the paper.
On the 156 class version of COCO, YOLO9000 achieved 16% mean Average Precision (mAP), and yes, while YOLO can detect 9,000 separate classes, the accuracy is not quite what we would desire.
“YOLOv3: An Incremental Improvement” (2018) Redmon and Farhadi YOLOv3 is significantly larger than previous models but is, in my opinion, the best one yet out of the YOLO family of object detectors.
We’ll be using YOLOv3 in this blog post, in particular, YOLO trained on the COCO dataset. https://pyimagesearch.com/2018/11/12/yolo-object-detection-with-opencv/ https://learnopencv.com/train-yolov8-on-custom-dataset/
Training on custom dataset on YOLOv8. https://learnopencv.com/train-yolov8-on-custom-dataset/
YOLO Neural Architecture Search NAS
Region-based Convolutional Neural Network RCNN
Python Packages for AI
numpy - large, multidimensional arrays and matrices, with mathematical functions to operate on these
scipy - scientific computing: optimization, linear algebra, integration, interpolation, special functions, FFT, signal and image processing, ODE solvers
scikit-learn - machine learning library: classification, regression, clustering, support vector machines, random forests, gradient boosting, k-means, DBSCAN
opencv - computer vision library
Warning
When using these packages simultaneously, I must watch out for the differences, for example:
- array dimensions reversed between numpy and opencv
- openCV: (x,y), (width, height), “columns major”, as in image processing
- numpy : (y,x), (height, width), “rows major”, as in inear algebra
AI terminology
Evaluation Metrics
For Binary Classification
binary classifier - yes or no balanced dataset - number of positives and negatives are approximately the same
accuracy = Ycorrect/Ytotal works well with a binary classifier and a balanced dataset
TP true positive, FP false positive TN true negative, FN false negative
Precision = TP / TP + FP
Recall = TP / TP + FN
To combine the two metrics:
F1 = Precision * Recall / Precision + Recall
mAP = mean Average Precision = calculated using the Precision Recall Curve
Precision / Recall = averaged across each class and all classes
For Object Detection
How to decide if an object is correctly located
IoU = Intersection over Union = I/U >= .5 indicates the object is correctly located
Support Vector Machine (SVM)
Historical Feature Extractors followed by SVM, multi stage architecture 2010 replaced by Feature Extractors followed by Deep Neural Net
Feature Extractors
edge - line of sudden change in pixel density corner - intersection of two edges
kernel
fixed or manually tuned convolutions
convolution - a mathematical operation on two functions f() and g(), that produces a third function f * g. The term convolution applies to the result function and to the process of computing it. It is defined as the integral of the product of the two functions after one is reflected about the y-axis and shifted. The integral is evaluated for all values of shift, producing the convolution function.
Taylor Series Expansion
Sobel Filter - to extract approximations of pixel intensity gradients
Harris Filter - to detect corners
Scale Intensity Feature Transform (SIFT) -
Histogram of Oriented Gradients (HOG) -
Clustering
K-Means - have to know number of clusters in advance
Hierarchical - start with every point in its own cluster. Then combine repeatedly until there's only one cluster. pn DBSCAN - ?
The VisDrone dataset was collected by the AISKYEYE team at the Machine Learning and Data Mining Lab of Tianjin University, China, and includes a variety of scenes under various weather and lighting conditions across 14 cities. The dataset provides still images taken by UAVs at different altitudes and positions with image resolutions up to 2000 × 1500. It contains 10 categories: pedestrian, people, bicycle, car, van, truck, tricycle, awning-tricycle, bus, and motor.Among them, the training set
collect the MS COCO [43], CARPK [44], VisDrone [45] and UAVDT [46] for comparison. VisDrone is a
Sliding window object detection
R-CNN
YOLO
R2-CNN effectively improved the detection performance of very small objects in large-scale remote sensing images although feature pyramid network (FPN) was effectiv
Deep learning-based general-purpose object detection algorithms can be divided into two categories. The first is two-stage methods based on candidate regions, such as the R-CNN series of algorithms [13], [14], [15]. The second is one-stage algorithms, including the YOLO series [16], [17], [18], [19], [20], [21] and SSD series [22], [23], [24]. The one-stage algorithm does not use a process for extracting candidate regions, and hence the accuracy is not as high as the two-stage algorithm, but it runs faster. Moreover, UAV aerial image object detection must operate in real time, and hence the one-stage algorithm was selected in this study. Currently, the most popular one-stage object detection method based on deep learning is YOLOX-X [21]. YOLOX-X runs fast and has a high accuracy on the natural scene image dataset MS COCO. However, the imaging angle of UAV aerial images is different from that of natural scene images.
Function approximator
Universal approximation theorem
open vocabulary “…their reliance on predefined and trained object categories limits their applicability in open scenarios.” https://arxiv.org/abs/2401.17270
SILT: Shadow-Aware Iterative Label Tuning
Object Recognition in Images Path detection and obstacle avoidance algorithms Gesture recognition, Mosaic generation, etc.
Scale Invariant Feature Transform SIFT Interest Point Detector available in opencv how to
multiple levels of gausian blur look at local area: point and neighboring points calc gradient and histogram of local area
scale and rotation rotation = heading
edge = rapid change in brightness within a small window
corner = intersection of two edges
blob = space surrounded by edges. has location, size, orientation, signature
Rotated Object Detection https://www.youtube.com/playlist?list=PLRhS6hiNUzEQs0ryTwxW4JCGsNLNyYmmX
defining rotated or oriented bounding box OBB x, y, w, h, θ opencv method: θ is 0 - 90°, quadrant I long edge method: θ is -90° - +90°, quadrant I or IV, width and height interchange, angle difference of 90°
anchor or proposal box
GIoU, DIoU, CIoU, Skew IoU Gaussian Wasserstein Distance GWD Kullback Leibler Divergence KLD Kalman Filter IoU KFIoU
pixel density - ppi, ppcm
pixel intensity - grayscale 0 to 255, 255 is intense, 0 is not
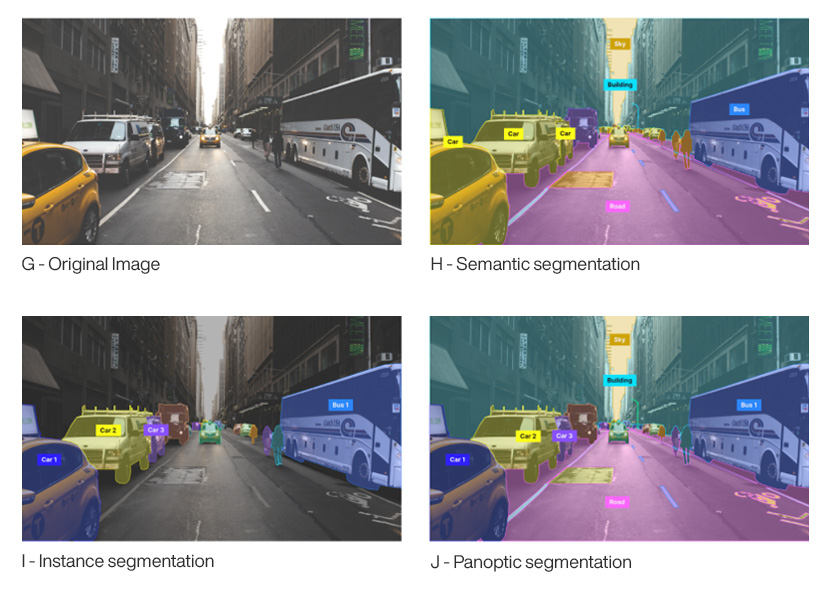
segmentation - Divide image into segments along object contours, so that each pixel is assigned to one segment. Colorize the image to distinguish the segments. Background segments may include grass, sky, road, building. Foreground segments may include car, person, tree, sign.
semantic segmentation - color identifies object class. All objects of a class have the same color.
instance segmentation - color identifies each individual object. Each object has a unique color and an associated id.
panoptic segmentation - semantic and instance segmentation combined. Color identifies class, and each object has an associated id.
object detection - Draw a bounding box around each object.
object classification - Identify the class of an object. Often used when there is only one object in an image. Classify it as cat or dog. Sometimes one layer will identify the objects, and a classifier will be used to determine the class of each object.
object localization - The bounding box identifies the location of an object within an image.
object recognition - match the object to similar instances in a database of images.
{kind=link}
{kind=link}
https://www.sentisight.ai/wp-content/uploads/2022/08/segmentation-example.png
{kind=link}
Note. The contour comes first. The bounding box can easily be drawn around the contour.
framework
model
configuration
backend
blob
outputs
Neural Net
Neural Network (NN) NN can be expressed as matrix math, or as circles and arrows NN combination of yes/no decisions Neuron reduces multiple stimulae to fire/no-fire output Recurrent nn, output feeds back in, feedback Feed-forward - not recurrent, no memory, no feedback
U Toronto Geof Hinton 60 million parameters 1000 categories Imagenet 2012, Geoffrey Hinton: “Imagenet Classification with deep convolutional neural networks” First useful application of neural nets.
https://www.youtube.com/watch?v=uXt8qF2Zzfo&t=1017s a nn is a function of inputs, weights, and threshholds z = f(x,w,t) a function approximator hill climbing, contour map partial derivative follow the gradient
YOLO - you only look once looks at the whole image in one pass, with one neural net. though it segments the image into SxS squares bounding box: cx, cy, w, h, confidence w and h are expressed as percentages of the full image dimenrsions IOU - intersection over union, the area of the intersection divided by the area of the union, of the two boxes, ground truth vs predicted, used as confidence score in YOLO
analyze image predict predict objects in image inputs: image, model, ground truth output: prediction
pro - fast enough to be used for real-time object detection, 24 FPS con - because it segments the image into a grid, and allows only one object per cell, it does not do well with small and/or overlapping objects.
comes in versions, YOLOv1, YOLOv3, YOLOv5s, etc
Datasets
VisDrone dataset
Framework
Darknet
Caffe
TensorFlow
ONNX
Network
YOLO
Model
A file of weights. Output from a training session. Binary data. Network-specific format.
Configuration
A description of the model.
Backend
Layers
Pipeline
proprocessing
3D pose estimation
YOLOv8-POSE
YOLO_NAS_POSE Deci is the company, SuperGradients is their product.
YOLO NAS POS
Code tutorial by “Code with Aarohi” https://www.youtube.com/watch?v=wg7uYDonGu0
Orientation
Google search: aerial photo object orientation
LLM
NLP
AI Code Writing
As of August 2024 AI models and tools for code writing from Grok
OpenAI: ChatGPT
VS Code, GitHub, Copilot: All from the Microsoft world.
nlp llm transformer
capabilities:
- code suggestions
- autocompletion
- generate a function from a prompt
stand-alone operation vs integrated with IDE
LLM coding assistant
- the model
- the corpora
- source code
- multiple languages
- organized into categories and contexts
- the trained model
- the interface:
- chatbot
- virtual assistant
- code completion plugin for an IDE
| Company | Product | Open Source | Languages | Comment |
|---|---|---|---|---|
| OpenAI | ChatGPT | No | ||
| OpenAI | Codex | No | ||
| GitHub | Copilot | No | Based on Codex, integrated into IDE's like VSCode. | |
| xAI | Grok | ? | ||
| Amazon | CodeWhisperer | No | For use with AWS | |
| Tabnine | Tabnine | No |
?:Tabnine AI-based code completion with support for over 30 programming languages. It's known for its ability to run locally or in the cloud, providing flexibility in deployment. Tabnine also emphasizes privacy by allowing developers to host their own models.
Meta:Code Llama free for both research and commercial use. Code Llama has been highlighted for its performance in coding tasks, even outperforming some versions of models like GPT-3.5 in certain benchmarks.
?:DeepSeek-v2-Coder Mentioned for its impressive performance in coding tasks, this model has been recognized for producing 100% compilable Java code in some evaluations, indicating high-quality code generation capabilities.
Anthropic: Claude While primarily known for its conversational abilities, Claude's latest iterations, like Claude 3.5, have been praised for coding proficiency, especially in understanding and generating code for less common libraries or languages.
- Local and Open-Source Models: There's a growing trend towards using open-source models like those based on LLaMA, Pythia, or even customized versions of these models for coding tasks. Tools like `ollama.nvim` for Neovim or platforms allowing you to run these models locally or on personal servers are becoming popular for those who prefer not to rely on cloud-based solutions.
xAI: Grok Although primarily known for its conversational abilities and integration with X (formerly Twitter), Grok's capabilities in understanding and potentially generating code could be inferred from its general language processing skills, though specific coding features might be less documented.
Each of these models or tools brings unique strengths to the table, from integration capabilities with existing workflows, support for a wide array of programming languages, to performance in generating high-quality, compilable code. The choice between them might depend on factors like integration with your current development environment, privacy concerns, cost, or specific coding task requirements. Remember, while these tools can significantly enhance productivity, they should be used as aids, with human oversight for critical or complex coding tasks.